本文是作者回答 我们能否用 LaTeX 记笔记跟得上讲座的速度,生发出来的博客文章。作者介绍了其工具和基本的操作思路。首先看看作者自己记录的笔记效果,洋洋洒洒 1700 页的内容:



这些讲义 - 包括数字 - 是在参加讲座时制作的,之后没有经过任何的编辑。为了说明使用 LaTeX 记笔记的可行性,作者专门制定了目标:第一个是在LaTeX中编写文本和数学公式应该与讲师在黑板上书写一样快:没有延迟。绘图数字几乎与讲师一样快。
作者所用的神器是 LaTeX + Vim。
上手 LaTeX
我们看看用Vim编辑LaTeX的场景,如下:

左边是Vim,右边是 pdf 阅读器 Zathura,它也有类似 Vim 的快捷键。
在 Vim 中,使用的 LaTeX 插件是 vimtex,它有语法高亮显示、目录视图、代码的同步等功能。
然后,使用 vim-plug 做如下配置:
Plug 'lervag/vimtex' let g:tex_flavor='latex' let g:vimtex_view_method='zathura' let g:vimtex_quickfix_mode=0 set conceallevel=1 let g:tex_conceal='abdmg'
最后两行控制的是“隐藏”功能。开启了这个功能,除了你光标所在的那一行之外,文本里夹杂的LaTeX代码就都会隐藏或者替换成其他符号。
比如说在下面动图里,隐藏了[,],$之后,没有了它们的干扰,整个文档就更易读。这个功能还会用∩替代\bigcap,∈替代\in等等。

有了这个设置,我就来到了这篇博文的关键:写作 LaTeX 的速度和老师在黑板上写的一样快。就是下面片段发挥的作用。
片段
什么是片段?
代码段是一段可重复使用的短文本,可以由其他一些文本触发。例如,当我键入 sign 并按下时 Tab,该单词 sign 将扩展为签名的片段内容:

片段也可以是动态的:当我键入today并按下时Tab,该单词today将被当前日期替换,并box Tab成为一个自动增大的框。


你甚至可以在另一个内部使用一个片段:

怎么创建片段?使用UltiSnips
管理片段的插件 UltiSnips,是这样配置的:
Plug 'sirver/ultisnips' let g:UltiSnipsExpandTrigger = '<tab>' let g:UltiSnipsJumpForwardTrigger = '<tab>' let g:UltiSnipsJumpBackwardTrigger = '<s-tab>'
代码sign段的代码如下:
snippet sign "Signature" Yours sincerely, Gilles Castel endsnippet
对于动态代码段,您可以将代码放在反引号之间,这些反引号``将在代码片段展开时运行。在这里,我使用bash格式化当前日期:date + %F。
snippet today "Date" `date +%F` endsnippet
您也可以在`!p ... `块内使用Python 。看一下代码box段的代码:
snippet box "Box" `!p snip.rv = '┌' + '─' * (len(t[1]) + 2) + '┐'` │ $1 │ `!p snip.rv = '└' + '─' * (len(t[1]) + 2) + '┘'` $0 endsnippet
这些Python代码块将被变量的值替换snip.rv。在这些块中,您可以访问代码段的当前状态,例如t[1]包含第一个制表位,fn当前文件名,...
LaTeX片段
使用片段,编写LaTeX比手动编写快得多。特别是一些更复杂的片段可以为您节省大量时间和挫折。让我们从一些简单的片段开始。
环境
要插入环境,我所要做的就是beg在一行的开头键入。然后我输入环境的名称,该名称在\end{}命令中被镜像。按下Tab将光标置于新创建的环境中。

此代码段的代码如下。
snippet beg "begin{} / end{}" bA
\begin{$1}
$0
\end{$1}
endsnippet这 b 意味着此代码段只会在行的开头A展开并代表自动展开,这意味着我不必按此 Tab 按钮展开代码段。制表符停止 - 也就是说你可以通过按 Tab 和 Shift+ 跳转到的地方 Tab 用 $1,, 表示 $2...,最后一个表示 $0。
内联和显示数学
我最常用的两个片段是 mk 和 dm。它们是负责启动数学模式的片段。第一个是内联数学的片段,第二个是显示数学的片段。

内联数学的片段是“聪明的”:它知道何时在美元符号后插入空格。当我开始在结束后直接输入一个单词时$,它会添加一个空格。但是,当我键入非单词字符时,它不会添加空格,例如在 ‘$p$-value’

此代码段的代码如下:
snippet mk "Math" wA
$${1}$`!p
if t[2] and t[2][0] not in [',', '.', '?', '-', ' ']:
snip.rv = ' '
else:
snip.rv = ''
`$2
endsnippet将w在第一行的末尾意味着这个片段将扩大在单词边界,所以例如hellomk不会扩大,但hello mk会。
显示数学的片段更简单,但也非常方便; 它让我永远不会忘记用句号结束方程式。

snippet dm "Math" wA \[ $1 .\] $0 endsnippet
子标题和上标
另一个有用的片段是下标。它的变化而变化 a1,以 a_1 及 a_12 对 a_{12}。

此代码段的代码使用正则表达式作为其触发器。当您键入一个字符后跟一个由其编码的数字 [A-Za-z]\d 或后跟_两个数字的字符时,它会扩展该片段:[A-Za-z]_\d\d。
snippet '([A-Za-z])(\d)' "auto subscript" wrA
`!p snip.rv = match.group(1)`_`!p snip.rv = match.group(2)`
endsnippet
snippet '([A-Za-z])_(\d\d)' "auto subscript2" wrA
`!p snip.rv = match.group(1)`_{`!p snip.rv = match.group(2)`}
endsnippet当您使用括号将正则表达式的部分包装在组中时,例如(\d\d),您可以通过match.group(i)Python 在扩展代码段中使用它们。
至于上标,我使用td,成为^{}。然而,对于平方,立方,补充和少数其他常见的,我使用专用的片段,如sr,cb和comp。

snippet sr "^2" iA
^2
endsnippet
snippet cb "^3" iA
^3
endsnippet
snippet compl "complement" iA
^{c}
endsnippet
snippet td "superscript" iA
^{$1}$0
endsnippet分数
我最方便的片段之一是分数片段。这使得以下扩展:
/ / → frac {}{}
3 / → frac {3}{}
4 pi ^ 2 / → frac {4 pi ^ 2}{}
(1 + 2 + 3) / → frac {1 + 2 + 3}{}
(1 + (2 + 3) /)→(1 + frac {2 + 3}{})
(1 + (2 + 3)) / → frac {1 + (2 + 3)}{
这一段代码比较简短:
snippet // "Fraction" iA
\\frac{$1}{$2}$0
endsnippet在第二和第三实施例成为可能使用正则表达式来匹配像表达式 3/,4ac/,6\pi^2/,a_2/,等。
snippet '((\d+)|(\d*)(\\)?([A-Za-z]+)((\^|_)(\{\d+\}|\d))*)/' "Fraction" wrA
\\frac{`!p snip.rv = match.group(1)`}{$1}$0
endsnippet正如您所看到的,正则表达式可能变得非常庞大,但这是一个应该解释它的图表:
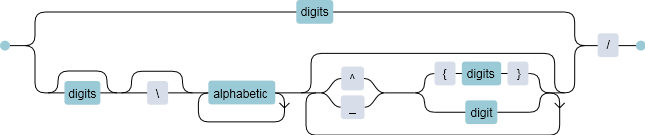
在第四和第五种情况下,它试图找到匹配的括号。因为使用 UltiSnips 的正则表达式引擎是不可能的,所以我使用了 Python:
priority 1000
snippet '^.*\)/' "() Fraction" wrA
`!p
stripped = match.string[:-1]
depth = 0
i = len(stripped) - 1
while True:
if stripped[i] == ')': depth += 1
if stripped[i] == '(': depth -= 1
if depth == 0: break;
i -= 1
snip.rv = stripped[0:i] + "\\frac{" + stripped[i+1:-1] + "}"
`{$1}$0
endsnippet分享的分数的最后一个片段是使用你的选择来制作分数的片段。你可以先选择一些文字然后按Tab,键入/并再按Tab一次来使用它。

代码使用${VISUAL}代表您选择的变量。
snippet / "Fraction" iA
\\frac{${VISUAL}}{$1}$0
endsnippetSympy和Mathematica
另一个很酷但很少使用的片段是使用 sympy 来评估数学表达式的片段。例如:sympy Tab展开到 sympy | sympy,然后 sympy 1 + 1 sympy Tab 展开到 2。

snippet sympy "sympy block " w
sympy $1 sympy$0
endsnippet
priority 10000
snippet 'sympy(.*)sympy' "evaluate sympy" wr
`!p
from sympy import *
x, y, z, t = symbols('x y z t')
k, m, n = symbols('k m n', integer=True)
f, g, h = symbols('f g h', cls=Function)
init_printing()
snip.rv = eval('latex(' + match.group(1).replace('\\', '') \
.replace('^', '**') \
.replace('{', '(') \
.replace('}', ')') + ')')
`
endsnippet对于 Mathematica 用户,你可以做类似的事情:

priority 1000 snippet math "mathematica block" w math $1 math$0 endsnippet priority 10000 snippet 'math(.*)math' "evaluate mathematica" wr `!p import subprocess code = 'ToString[' + match.group(1) + ', TeXForm]' snip.rv = subprocess.check_output(['wolframscript', '-code', code]) ` endsnippet
Postfix片段
我认为值得分享的其他一些代码段是 postfix 代码段。这种片段的例子是 phat→ \hat{p} 和 zbar→ \overline{z}。类似的片段是后缀矢量,例如 v,.→ \vec{v} 和 v.,→ \vec{v}。顺序,和.无关紧要,所以我可以同时按下它们。这些片段可以节省时间,因为您可以输入讲师在黑板上写的相同顺序。

请注意,我仍然可以使用 bar 和 hat 前缀,因为我已经添加了较低的优先级。这些代码段的代码是:
priority 10
snippet "bar" "bar" riA
\overline{$1}$0
endsnippet
priority 100
snippet "([a-zA-Z])bar" "bar" riA
\overline{`!p snip.rv=match.group(1)`}
endsnippetpriority 10
snippet "hat" "hat" riA
\hat{$1}$0
endsnippet
priority 100
snippet "([a-zA-Z])hat" "hat" riA
\hat{`!p snip.rv=match.group(1)`}
endsnippetsnippet "(\\?\w+)(,\.|\.,)" "Vector postfix" riA
\vec{`!p snip.rv=match.group(1)`}
endsnippet其他片段
我有大约100个其他常用的片段。它们在 这里 可用。其中大多数都很简单。例如,!> 成为 \mapsto,->成为 \to 等

fun变成f: \R \to \R :,!>→ \mapsto,->→ \to,cc→ \subset。

lim变成\lim_{n \to \infty},sum→ \sum_{n = 1}^{\infty},ooo→\infty


课程特定的片段
除了我常用的片段,我还有特定课程的片段。这些是通过将以下内容添加到我的.vimrc:
set rtp+=~/current_course
哪里 current_course 是我目前激活的课程的符号链接(更多关于在另一篇博文中的内容)。在该文件夹中,我有一个文件 ~/current_course/UltiSnips/tex.snippets,其中包含课程特定的片段。例如,对于量子力学,我有 bra / ket 表示法的片段。
<a| | → | \bra{a} |
<q| | → | \bra{\psi} |
|a> | → | \ket{a} |
|q> | → | \ket{\psi} |
<a|b> | → | \braket{a}{b} |
正如 \psi 在量子力学中经常使用的那样,我在扩展时替换 q 了 braket 中的所有实例 \psi。

snippet "\<(.*?)\|" "bra" riA
\bra{`!p snip.rv = match.group(1).replace('q', f'\psi').replace('f', f'\phi')`}
endsnippet
snippet "\|(.*?)\>" "ket" riA
\ket{`!p snip.rv = match.group(1).replace('q', f'\psi').replace('f', f'\phi')`}
endsnippet
snippet "(.*)\\bra{(.*?)}([^\|]*?)\>" "braket" riA
`!p snip.rv = match.group(1)`\braket{`!p snip.rv = match.group(2)`}{`!p snip.rv = match.group(3).replace('q', f'\psi').replace('f', f'\phi')`}
endsnippet上下文
在编写这些片段时需要考虑的一件事是,“这些片段会与长与常用的文本冲突吗?”
例如,在英语中大约有72个单词包含sr,这意味着当输入disregard这个词时,sr会扩展到^2,出现一个di^2egard。
这个问题的解决方案是,为代码片段添加上下文。
通过使用 Vim 的语法突出显示,可以确定UltiSnips是否应该扩展片段,这取决于你使用的是数学还是文本。
global !p
texMathZones = ['texMathZone'+x for x in ['A', 'AS', 'B', 'BS', 'C',
'CS', 'D', 'DS', 'E', 'ES', 'F', 'FS', 'G', 'GS', 'H', 'HS', 'I', 'IS',
'J', 'JS', 'K', 'KS', 'L', 'LS', 'DS', 'V', 'W', 'X', 'Y', 'Z']]
texIgnoreMathZones = ['texMathText']
texMathZoneIds = vim.eval('map('+str(texMathZones)+", 'hlID(v:val)')")
texIgnoreMathZoneIds = vim.eval('map('+str(texIgnoreMathZones)+", 'hlID(v:val)')")
ignore = texIgnoreMathZoneIds[0]
def math():
synstackids = vim.eval("synstack(line('.'), col('.') - (col('.')>=2 ? 1 : 0))")
try:
first = next(
i for i in reversed(synstackids)
if i in texIgnoreMathZoneIds or i in texMathZoneIds
)
return first != ignore
except StopIteration:
return False
endglobal现在,您可以添加context "math()"到仅在数学上下文中展开的片段。
context "math()" snippet sr "^2" iA ^2 endsnippet
请注意,“数学上下文”是一个微妙的事情。有时您可以使用在数学环境中添加一些文本 \text{...}。在这种情况下,您不希望片段扩展。但是,在以下情况中:\[ \text{$...$} \] 它们应该扩展。这就是 math 上下文代码有点复杂的原因。以下动画说明了这些细微之处。

结论
在 Vim 中使用片段,编写 LaTeX 不再是烦恼,而是一种乐趣,结合动态拼写检查,它可以实现舒适的数学笔记设置。但是缺少一些部分,例如以数字方式绘制图形并将它们嵌入到 LaTeX 文档中。
相关链接资源,工具传送门:
Linux和Mac系统自带Vim。
Windows版本Vim:
https://ftp.nluug.nl/pub/vim/pc/gvim81.exe
Vim插件管理:
https://github.com/junegunn/vim-plug
Vim LaTeX插件:
https://github.com/lervag/vimtex
窗口平铺管理器:
https://github.com/baskerville/bspwm
管理Vim片段工具:
https://github.com/SirVer/ultisnips
如果你用不惯Vim,还有Emacs、Atom、VS Code、Sublime,它们都有LaTeX插件,总有一款文本编辑器适合你。想要熟悉更多的LaTeX使用方法,就需要系统地学习,平时多加练习也必不可少。



111